

AI による画像生成技術は、最近注目されている分野の一つです。しかしながら、AI 技術に精通している人以外には、画像生成 AI を使うことは難しいものと思われています。また、画像生成 AI に適したコンピューターを持っていない場合、始めることができないという人もいるかもしれません。
そこで、この記事では、M1 Mac を使って手軽にできる画像生成 AI 「Stable Diffusion」について紹介します。初心者の方でも理解しやすいように、基本的な使い方や始め方を丁寧に解説します。M1 Mac で Stable Diffusion を使えば、高価なコンピューターを持っていなくても、簡単に画像生成AIを始めることができます。
この記事を読むことで、M1 Mac を持っている方は、手軽に画像生成AIを始めることができるようになります。初心者の方でも、わかりやすい解説によって、Stable Diffusion の使い方や始め方が理解できるようになります。また、高価なコンピューターを用意しなくても、M1 Mac を使って AI 技術に触れることができるようになります。AI 技術に興味のある方、副業として AI 技術を活用したい方は、ぜひこの記事を読んでみてください。
Mac で Stable Diffusion を動かすために必要なもの

私は、以下のスペックのMacを使用しました。Mac で Stable Diffusion を動かすためには、Apple M1/M2 チップ搭載が必要です。高性能な NVIDIA の GPU が無くても、画像生成が行なえます。
- モデル:Mac mini (M1, 2020)
- チップ:Apple M1チップ
- メモリ:16GB
- ストレージ:512GB
Windows パソコンに高性能な GPU が搭載されていれば、1枚の画像生成が数秒で終わります。しかし、上記の Mac mini では 1 枚に 30 秒 〜 1 分 30 分かかります。処理速度は遅いですが、使い方によっては十分な画像生成速度です。
なぜ、早い画像生成が求められるのか
一般的には大量の画像を生成して、うまくできた画像を選択する方法が取られます。この方法では利用されないムダな画像を大量生産してしまいます。大量の画像を仕分ける方が時間が取られます。できるだけムダな画像を作らないように、プロンプトやネガティブプロンプトなどの設定を工夫する方が時間も電気代も節約できます。
失敗画像を減らし、ムダをなくす
画像生成 AI を学習して上達してくると、何百枚も画像を生成しなくても、20 〜 30 枚で欲しい画像を生成できるようになるでしょう。上達すると GPU 性能を使わなくても、目的の画像が得られるようになります。また、フォトレタッチソフトなどを利用すれば画像の加工ができます。
画像生成とは何か?

画像生成とは、人工知能によって画像を生成することを指します。従来の画像処理技術では、既存の画像を加工して新しい画像を生成することができましたが、画像生成 AI を使うことで、まったく新しい画像を生成することが可能になります。
画像生成 AI には、様々な手法がありますが、最近注目されているのが「Deep Learning」を用いた手法です。Deep Learning は、多層のニューラルネットワークを用いて、大量のデータから学習を行うことで、高度な画像生成が可能になります。
具体的には、画像生成 AI に学習させたデータセットから、新しい画像を生成することができます。例えば、犬の画像を学習させたデータセットを使って、新しい犬の画像を生成することができます。生成された画像は、人間が描いた絵や写真と同じように見えることがあります。
このように、画像生成AIを使うことで、従来の手法では表現できなかった様々な画像を生成することができます。また、画像生成 AI を使うことで、新しいデザインやアートワークを生み出すことも可能になります。
M1 Mac で使える画像生成AI「Stable Diffusion」は、Deep Learning による手法を用いて、高度な画像生成が可能です。初心者でも簡単に始めることができるため、画像生成に興味がある人にとっては、手軽に取り組める技術と言えます。
画像生成が注目されている理由

画像生成AIは、人間の創造力やイメージ力に近い作業を自動化することができます。今後の AI 技術の進化によって、より高度な画像生成が可能になり、様々な分野での応用が期待されています。画像生成が注目されている理由には、以下のようなものがあります。
様々な表現が可能になる
従来の手法では、人間が描いた絵や写真を加工することができましたが、新しいデザインやアートワークを生み出すことは困難でした。しかし、画像生成AIを使うことで、まったく新しい画像を生成することができるため、様々な表現が可能になりました。
デザインやアートに新しいアプローチが生まれる
画像生成AIを使うことで、新しいデザインやアートワークを生み出すことができるだけでなく、これまでにないアプローチが生まれます。人間が描いた絵や写真とは異なる、独自の美しさや特徴を持った画像を生成することができるため、新しい視点やアイデアが生まれる可能性があります。
創造性やアイデアを刺激することができる
画像生成AIを使うことで、自分が思い描くような画像を生成することができます。そのため、創造性やアイデアを刺激することができ、新しいアートワークやデザインを生み出すことができます。
ビジネスにおいても利用される可能性がある
画像生成 AI は、ビジネスにおいても利用される可能性があります。例えば、商品のパッケージや広告のデザインに利用することができます。また、SNS のアイコンやロゴのデザインにも利用されています。
様々なデザインの可能性を引き出すことができる

Stable Diffusion を使用することで、様々なデザインの可能性を引き出すことができます。以下に、M1 Mac で Stable Diffusion を使ってデザインを作成する際の具体的な例をいくつか紹介します。
アートワークの作成
Stable Diffusion を使用することで、アートワークの作成が可能になります。例えば、抽象的なアートワークやグラフィックデザインを生成することができます。また、手書きのイラストを自動的に生成することもできます。
テクスチャの生成
Stable Diffusionを使用することで、様々なテクスチャを自動的に生成することができます。例えば、木材や石材などの質感のあるテクスチャを自動的に生成することができます。
ロゴの作成
Stable Diffusion を使用することで、様々なロゴを自動的に生成することができます。例えば、文字やアイコンを自動的に組み合わせて、独自のロゴを作成することができます。
ウェブサイトのデザイン
Stable Diffusion を使用することで、ウェブサイトのデザインを自動的に生成することができます。例えば、ウェブサイトのレイアウトや色合い、フォントなどを自動的に設定することができます。
創造性やアイデアを刺激することができる

Stable Diffusionを使用することで、創造性やアイデアを刺激することができます。以下に、M1 MacでStable Diffusionを使って創造性やアイデアを刺激する方法をいくつか紹介します。
イメージ検索との組み合わせ
Stable Diffusion は、イメージ検索と組み合わせて使用することができます。例えば、特定のキーワードでイメージ検索を行い、その結果を Stable Diffusion に入力することで、よりクリエイティブな画像を生成することができます。
ランダムな画像生成
Stable Diffusion は、ランダムな画像生成も可能です。ランダムな画像生成を行うことで、想像力を刺激し、新しいアイデアやアートワークの制作に役立てることができます。
既存のデザインの改良
Stable Diffusion を使用することで、既存のデザインを改良することもできます。例えば、既存のロゴやアートワークを Stable Diffusion に入力し、改良版のデザインを自動的に生成することができます。
テストデザインの作成
Stable Diffusion を使用することで、テストデザインを作成することができます。テストデザインは、実際の製品やアートワークを作成する前に、デザインのアイデアを検討するために使用されます。
画像生成 AI を使った副業のアイデア

画像生成AIを使った副業として、以下のようなアイデアがあります。
デザイン制作の支援
Stable Diffusion を使った画像生成は、デザイン制作の支援に役立ちます。例えば、広告やポスターのデザイン、Web サイトの UI/UX デザインなどを手掛ける場合、Stable Diffusion を使ってデザインのアイデアを生成することで、より創造的なデザインを制作することができます。
マーケティング支援
Stable Diffusion を使った画像生成は、マーケティング支援にも役立ちます。例えば、商品画像やバナー広告の制作を手掛ける場合、Stable Diffusion を使って、商品やブランドイメージに合った画像を生成することができます。
イラスト制作
Stable Diffusion を使った画像生成は、イラスト制作にも応用が可能です。例えば、漫画や絵本のイラスト制作を手掛ける場合、Stable Diffusion を使って、より表現力豊かなイラストを制作することができます。
グッズ制作
Stable Diffusion を使った画像生成は、グッズ制作にも活用が可能です。例えば、Tシャツやステッカー、ポストカードなどのグッズ制作を手掛ける場合、Stable Diffusion を使って、オリジナルのデザインを生成することができます。
イラストレーターが制作するイラストと AI イラストの違い

画像生成 AI によるイラストとイラストレーターが作成するイラストは、大きく異なります。以下に、それぞれの違いを専門家の意見を交えながら具体例を交えて説明します。
創造性の違い
画像生成 AI によるイラストは、ある程度のパターンがあらかじめプログラムされているため、イラストレーターが作成するイラストに比べて、創造性に欠けるという指摘があります。AI が生成するイラストは、プログラムされた条件やルールに沿って生成されるため、同じパターンのイラストが何度も生成されることがあります。
一方、イラストレーターが作成するイラストは、その人の感性や経験に基づいた創造性に富んだ作品が生み出されます。例えば、同じキャラクターを描いた場合でも、それぞれのイラストレーターが異なる表情やポーズ、雰囲気などを表現することができます。
精度の違い
画像生成AIによるイラストは、高い精度で画像を生成することができます。例えば、写真を基に人物のイラストを生成する場合でも、細かい特徴や色味を正確に再現することができます。
しかし、イラストレーターが作成するイラストは、あえて線のゆらぎや手描きのタッチなど、精度を落とした表現がされることがあります。それによって、より人間味や温かみのある作品が生まれます。
オリジナリティの違い
画像生成 AI によるイラストは、あくまでプログラムに基づいた生成であるため、他の作品との差別化が難しいという問題があります。一方、イラストレーターが作成するイラストは、その人の持つ感性や経験に基づいたオリジナルの作品が生み出されます。これによって、他とは違った独自性のある作品を生み出すことができます。
好みの反映のしやすさ
AI 技術の進歩によって、今後はAIが創造性に富んだオリジナルなイラストを生成することも可能になるかもしれません。しかし、イラストレーターが作成する作品には、あくまでもその人の個性が反映されています。また、イラストレーターは手描きのタッチや独自のスタイルを持っており、その作品には人間味や温かみが感じられます。
例えば、同じ動物を描いた場合でも、AI が生成したイラストは正確でリアルな印象を与える一方で、イラストレーターが作成したイラストは、それぞれの個性や表現力が感じられることがあります。
つまり、画像生成 AI によるイラストとイラストレーターが作成するイラストは、それぞれ特徴があり、異なる魅力を持っています。どちらも一長一短ですが、それぞれの強みを活かした作品を生み出すことが大切です。
画像生成 AI 「Stable Diffusion」とは?

画像生成AI「Stable Diffusion」とは、OpenAI が開発した、高度な画像生成を実現するための Deep Learning 技術です。Stable Diffusion は、画像生成に必要な条件を確率的に推定し、より自然な画像を生成することができます。
Stable Diffusion は、条件付き GAN を発展させた手法を用いています。GAN は、生成器と判別器の2つのモデルを用いて、新しい画像を生成することができます。しかし、生成器が生成した画像が自然ではない場合があります。そのため、Stable Diffusionで は、画像生成に必要な条件を確率的に推定することで、より自然な画像を生成することができます。
Stable Diffusion は、高速な画像生成が可能なため、リアルタイムでの応用も可能です。さらに、Stable Diffusion は、様々な画像生成タスクに対応しています。例えば、画像の修復や画像の変換、新しい画像の生成などが可能です。
M1 Mac 上でも利用できる Stable Diffusion は、初心者でも簡単に始めることができる画像生成 AI の 1 つです。利用するには、Python や PyTorch などのプログラム言語が必要ですが、その他の環境設定は比較的簡単です。
Stable Diffusion を使うことで、初心者でも様々な創造的なアイデアや新しいデザインを生み出すことができます。例えば、Stable Diffusion を使って、既存の画像を加工して新しいデザインを生み出すことができます。また、Stable Diffusion を使って、まったく新しい画像を生成することもできます。
画像生成AI「Stable Diffusion」は、高度な画像生成を簡単に実現できるため、注目を集めています。初心者でも手軽に始めることができるので、興味がある人はぜひ取り組んでみてください。
画像生成 AI の利用比較

Mac で画像生成 AI を利用するには、Mac アプリを利用する方法、Stable Diffusion をインストールする方法があります。画像生成の自由度の高さと画像生成の上達には、Mac に Stable Diffusion をインストールする方法がおすすめです。Stable Diffusion のインストールは、手順通りに行えば初心者でもそれほど難しくありません。
| DiffusionBeeなど Macアプリを インストール | M1/M2 Macに Stable Diffusionを セットアップ | Google Colabに Stable Diffusionを セットアップ | |
|---|---|---|---|
| 環境準備の容易さ | |||
| 環境設定の保存 | |||
| 初心者向き | |||
| 画像生成の速度 | |||
| ランニングコスト | |||
| 利用可能時間 | |||
| 自由な画像生成 | |||
| 自由なモデル選択 | |||
| 自由なメソッド選択 | |||
| 手軽な画像生成 | |||
| 高度な画像生成 | |||
| 画像生成AIの学習 |
Mac や Google Colab に Stable Diffusion をインストールすると、ボーンや画像を利用したポーズ指定などの機能を加えることもできる自由度の高さが魅力です。Stable Diffusion は基本的にターミナルアプリから英数字や記号の文字列を書いて実行します。
しかし、もっと簡単に操作できるよういくつかの Web UI が公開されています。これら UI を使うと、マウス操作ができるようになるので操作が簡単になるだけでなく、操作の間違いも少なくて済みます。
Mac アプリ
DiffusionBee は、Mac 上で Stable Diffusion を Mac アプリの形で利用できます。Mac の機械学習エンジンを利用できるアプリもあります。DiffusionBee なら Mac に Stable Diffusion をインストールして利用する AUTOMATIC1111 や InvokeAI の半分程度の時間で画像を作ることができます。はじめて画像生成を体験するのに、以下のようなアプリがおすすめです。
- Draw Things App
- Diffusers App
- DiffusionBee
画像生成の楽しさがわかってくると、自分好みの画像を作りたくなります。ポーズの指定、同じキャラクターで異なる画像を生成したいなどのクリエイティブな欲求が湧いてくるはずです。ランダムに大量の画像を生成して、望む画像を探すよりも作りたい画像をコントロールする方がずっと効率的です。そうすると様々な最新の機能を追加したくなると思います。
そうしたときに Stable Diffusion を Mac にインストールして、より簡単に操作できように Web UI を使うと良いでしょう。例えば、「〇〇風」のイラストやキャラクターなどの画像を作りたいときに、Mac アプリではモデルやメソッドを自由に選べないアプリもあるので、目的に応じて選ぶと良いでしょう。
Google Colab
また、Mac 上で画像を生成する以外にも、Google Colab に Stable Diffusion をインストールして行う方法もあります。この方法ならウェブブラウザで実行できるので、Windows でも Mac でも利用できます。パソコンの性能に左右されないので、誰でも試せる方法です。
しかし、Google Colab の GPU は利用に制限があるため、利用上限を超えてしまうと、高速な画像生成が行なえません。Google Colab には、GPU リソースを長時間使うために Pro プランや Pro+ プランがあります。いずれも有料のため、長期間利用するなら、Windows パソコンに搭載するためのGPUが買った方が安いかもしれません。もし、Windows パソコンを持っているなら、GPU の購入も検討してみると良いでしょう。
Google Colab の不便ポイント
Google Colab で Stable Diffusion を利用するときの毎回インストールやセットアップが必要です。この作業に 5 分程度かかり、すぐに画像を生成することができないのが難点です。また、環境設定した情報も消えてしまいますので、自分でバックアップするなどの作業が必要です。インストールするパッケージが、いつも一緒とは限りません。突然動かなくなってしまうことも想定しておきましょう。
こうしたことを自分で解決するには、Linux のファイルシステムやコマンドの知識が必要になります。Windows ユーザーや IT 技術の初心者には、やや難解かもしれません。わからないことがでてきたときに、自分で調べて解決する必要があります。Python プログラミングの学習に Google Colab を利用したことがある人なら難しくないでしょう。
初心者でも簡単に始められる

Stable Diffusion を使って画像生成を始めることは、初心者でも比較的簡単にできます。以下に、初心者でも簡単に始められる方法をいくつか紹介します。
AUTOMATIC1111 は人気のあるStable DiffusionのWeb UIの一つです。初心者に優しく、サイトページからマウスで操作して Stable Diffusion の機能を簡単に利用できます。複数の画像をまとめて生成することもマウス操作で行えるので、文字でコマンド入力することが苦手な人にもおすすめです。生成済み画像はサイトページに表示されるので、画像の出力先フォルダを開かずに画像を確認できます。
Windows でも利用される Web UI なので、新しい機能が追加されたり、動作の問題が解決される速度が早いです。困ったときにコミュニティの情報を検索して自分で対処しやすいです。
Stable Diffusion が注目されている理由

Stable Diffusion は、高度な画像生成技術を実現することができます。従来のGANに比べ、より自然な画像を生成することができるため、ビジネスや芸術の分野での利用が期待されています。
また、Stable Diffusion は、高速でリアルタイムの応用が可能なため、ビデオや映画など、リアルタイム性が求められる分野でも利用されています。また、Stable Diffusion は、様々な画像生成タスクに対応しているため、修復や変換、新しい画像の生成など、多様な用途で利用されています。
さらに、Stable Diffusion は、オープンソースで公開されており、誰でも自由に使用することができます。そのため、研究者や開発者、デザイナーなどが、自由に Stable Diffusion を利用し、新しいアプリケーションやアイデアを生み出すことができます。
最後に、Stable Diffusion は、OpenAI という世界的に有名なAI研究機関によって開発されたため、その技術的信頼性が高く、信頼されています。
以上が、Stable Diffusion が注目されている理由についての説明です。Stable Diffusion は、高度な技術を駆使した画像生成技術であり、多様な用途に応用できるため、今後ますます注目が集まることが予想されます。
Stable Diffusion の基本的な概要の説明

Stable Diffusion は、Deep Learning を用いた画像生成技術の1つです。画像生成に必要な条件を推定することで、より自然な画像を生成することができます。
Stable Diffusion では、2つのニューラルネットワークが使用されます。1つは、条件推定器であり、もう1つは、生成器です。条件推定器は、生成器が生成する画像に必要な条件を確率的に推定します。そして、その推定された条件を生成器に与え、より自然な画像を生成することができます。
また、Stable Diffusion では、損失関数の最小化により、より自然な画像を生成することができます。生成器が生成する画像と、本物の画像を判別する判別器があります。判別器は、生成器が生成した画像を本物の画像と判別するように学習します。生成器は、判別器に騙されないように、より自然な画像を生成するように学習します。
Stable Diffusion は、高度な画像生成が可能であり、様々な画像生成タスクに対応しています。例えば、画像の修復や画像の変換、新しい画像の生成などが可能です。また、リアルタイムでの応用も可能であり、ビジネスや芸術の分野でも利用されています。
Stable Diffusion を使用するためには、Python や PyTorch といったプログラム言語が必要ですが、初心者でも比較的簡単に始めることができます。また、Stable Diffusion は、オープンソースで公開されており、誰でも自由に使用することができます。
M1 Mac で Stable Diffusion を使った画像生成の魅力

Stable Diffusionを使用することで、画像生成における多くの課題を解決することができます。以下に、M1 MacでStable Diffusionを使った画像生成の魅力をいくつか紹介します。
現実的な画像生成が可能
Stable Diffusion を使用することで、より現実的な画像生成が可能になります。例えば、空や海などの自然風景を自然な形で生成することができます。Stable Diffusion は、生成された画像をより自然に見せるために、細部まで計算して生成することができます。
高画質な画像が生成可能
Stable Diffusion は、高画質な画像の生成にも対応しています。生成された画像は、リアルな質感とディテールを持ち、プロのレベルの画像生成が可能です。
多様性のある画像生成が可能
Stable Diffusion を使用することで、多様な画像生成が可能になります。例えば、人物の顔を生成する場合でも、性別や年齢、表情などの多様性がある画像を生成することができます。
ユーザーが自由にコントロールできる
Stable Diffusion は、ユーザーが自由にコントロールできることが特徴です。例えば、生成画像における特定の属性を変更したり、背景を変えたりすることができます。
初心者にもおすすめ AUTOMATIC1111 とは

AUTOMATIC1111 は、Stable DiffusionのWeb UI です。AUTOMATIC1111 を使用することで、Stable Diffusion をより簡単に操作することができます。AUTOMATIC1111 には、以下のようなメリットがあります。
GUIでの操作が可能
AUTOMATIC1111 は、グラフィカルユーザーインターフェイス( GUI )で操作が可能です。プログラミングの知識がない初心者でも、GUIを使って簡単に操作することができます。
ビジュアルなフィードバック
AUTOMATIC1111 では、生成された画像をリアルタイムでプレビューすることができます。ビジュアルなフィードバックを受けながら、より自然な画像を生成することができます。
AUTOMATIC1111 以外の選択肢

Stable Diffusion を利用する方法として、次のような選択肢もあります。
- Prompt To Image
- InvokeAI
InvokeAI は、AUTOMATIC1111 と同様にわかりやすい操作画面で画像生成できます。画像生成に要する時間もほぼ同じです。画像生成時のステップ数が増えると InvokeAI の方が若干短い時間で生成が完了します。しかし、AUTOMATIC1111 には生成以外にも多彩な機能を備えるで人気を二分しています。
M1 Mac で Stable Diffusion を使って画像生成を始めよう

初心者でも比較的簡単に始めることができるため、興味のある方はぜひ取り組んでみてください。また、自分のアイデアを形にするために、Stable Diffusion を使って画像生成に挑戦してみるのも良いでしょう。
Stable Diffusion は、Python や PyTorch といったプログラム言語を使って実行することができます。M1 Mac で Stable Diffusion を使って画像生成を始めるには、以下の手順を行います。
M1 Mac で Stable Diffusion を使うための準備方法

Stable Diffusionのインストールとセットアップなどの作業は、以下の通りです。おおよそ 30 分程度かかります。インストール作業で、Mac にログインしているユーザーのパスワードが求められることがあります。
Homebrew のインストール
Stable Diffusion で利用される各種パッケージをインストールできるようにするために、パッケージマネージャーの Homebrew を Mac にインストールします。
まず、Homebrewのサイトにアクセスして、macOS用パッケージマネージャーをインストールします。
サイトには、以下のような Mac に Homebrew をインストールするためのコードが記載されています。このコードをコピーするか、以下のボックスから「Copy」ボタンを押してコピーします。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
macOS のターミナルアプリを開きます。通常は、「その他」フォルダに格納されているはずです。ターミナルアプリの画面が表示されたら「⌘+V」キーを押して、コードを貼り付けて Enter キーを押してインストールを実行します。
Python と必要なパッケージのインストール
Python と必要なパッケージをインストールします。macOS のターミナルアプリに以下のコードを貼り付けて Enter キーを押して実行します。
brew install cmake protobuf rust python@3.10 git wget
注意点として、Python のバージョンが 3.10 でないと、Stable Diffusion を実行するときにエラーになります。そのため「python@3.10」のようにして、バージョン指定でインストールします。「3.10.〜」のように「〜」の部分の数字は影響しないので気にしなくても大丈夫です。
AUTOMATIC1111 をクローン
Stable Diffusion の Web UI である AUTOMATIC1111 をインストールします。macOS のターミナルアプリに以下のコードを貼り付けて Enter キーを押して実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
ユーザーフォルダ内に「stable-diffusion-webui」フォルダが作られます。この中にStable Diffusion や AUTOMATIC1111 のプログラムが格納されます。
Stable Diffusion で使うモデルを用意する
作成したい画像のスタイルに合わせて、Stable Diffusion で実行するモデルを用意します。Stable Diffusionでとりあえず画像生成してみるには、「v1.5 model」をダウンロードして、「stable-diffusion-webui/models/Stable-diffusion」のフォルダに保存します。
「stable-diffusion-webui」→「models」→「Stable-diffusion」フォルダを開き、「v1-5-pruned-emaonly.ckpt」ファイルが格納されていれば大丈夫です。
アニメ風の画像を作りたい方は、「モデルと VAE をダウンロード」の項目も併せてご覧ください。
AUTOMATIC1111 の環境設定(オプション)
PyTorch 2 でスピードアップ
執筆時点では機械学習フレームワークに PyTorch 1 が使われていました。この代わりに、最新の PyTorch 2 をインストールすると 10 〜 20% ほど処理速度が早くなります。もし、次の操作が難しそうなら、ここでの作業をスキップして「AUTOMATIC1111の実行」から始めてください。
まず、AUTOMATIC1111 を実行時に処理されるコマンドを変更します。操作としては、ユーザーフォルダ内に「stable-diffusion-webui」フォルダを開き、テキストでディタなどで「webui-user.sh」を開きます。
「export TORCH_COMMAND=」で始まる行を「export TORCH_COMMAND=”pip install –pre torch==2.0.0.dev20230131 torchvision==0.15.0.dev20230131 -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html”」に書き換えて保存します。
PyTorch 2 のインストールが失敗したら
もし、次の「AUTOMATIC1111の実行」でエラーなどによりターミナルアプリの最後の表示に「To create a public link, set `share=True` in `launch()`.」が表示されなかったら、ユーザーフォルダ内に「stable-diffusion-webui」フォルダを削除して、上記の「AUTOMATIC1111をクローン」からやり直してみて下さい。
AUTOMATIC1111 の実行
以下のコマンドを実行すると、ユーザーフォルダ内に「stable-diffusion-webui」フォルダにカレントパスが移動します。(ターミナルアプリで「stable-diffusion-webui」フォルダを開いた状態になります。)その後、「;」の後ろの「./webui.sh」が実行されStable DiffusionおよびWebUI(AUTOMATIC1111)が起動します。
cd ~/stable-diffusion-webui;./webui.sh
初回実行時は、関連パッケージのインストールが行われるので、通信速度などにもよりますが 10 分程度時間がかかります。2回目以降の実行は、インストール処理がないため、1 分以内に起動します。
起動が完了するとターミナルアプリの最後の表示に「To create a public link, set `share=True` in `launch()`.」が表示されます。その2行上に「Running on local URL: http://127.0.0.1:7860」が表示されています。このURLアドレスをウェブブラウザで開きますので「http://127.0.0.1:7860」部分をコピーします。
ターミナルアプリは閉じずに開いたままにしましょう。ターミナルアプリを停止すると、Stable Diffusion や AUTOMATIC1111 も停止して使えなくなります。
エラー回避方法
通常は、30秒ほどで画像が生成されます。Macの搭載メモリが8GBなど少ない場合、「steps 20」で「512 x 512」の画像の生成に 1 分以上かかる場合など、以下のコマンド実行すると改善するかもしれません。
cd ~/stable-diffusion-webui;./webui.sh --opt-split-attention-v1
メモリ不足の警告表示、アクティビティモニタのメモリプレッシャーでグラフが赤色になる場合、以下のコマンド実行を試して見て下さい。複数アプリを実行している場合、使用していないアプリを停止するのも有効です。
cd ~/stable-diffusion-webui;./webui.sh --opt-split-attention-v1 -medvram
Stable Diffusion WebUI にアクセス
ウェブブラウザのアドレスバーに以下のアドレスを貼り付けてサイトを開きます。
http://127.0.0.1:7860/
AUTOMATIC1111 の終了
Stable Diffusion の利用が終了したらプログラムを停止します。最初に「http://127.0.0.1:7860」を表示させているウェブブラウザのタブを閉じます。
その後、ターミナルアプリの画面で「Ctrl+C」キーを押して、数秒後に「Enter」キーを押します。そうすると、画面がスクロールされます。続けて「exit」と入力して「Enter」キーを押すと、ターミナルアプリの画面が閉じられます。ウィンドウ左上の赤丸の閉じるボタンをクリックしても良いです。最後に、メニューバーからターミナルを終了します。
以上で、M1/M2 MacにStable Diffusionの実行環境が完成です。
EasyNegative のインストール

Hugging Face から EasyNegative のファイルをダウンロードしてインストールします。EasyNegative のページを開き、
「stable-diffusion-webui」→「embeddings」フォルダにダウンロードしたファイルを格納します。
M1 Mac で Stable Diffusion を使った画像生成の手順

AUTOMATIC1111 を使用した Stable Diffusion による画像生成はとっても簡単です。
ここでは操作を説明します。「①」のプロンプト(Prompt)に「Apple」、「②」のネガティブプロンプト(Negative prompt)に「EasyNegative」の文字を入力しました。最後に「③」の「Generate」ボタンをクリクします。30 秒ほどで画像が表示されます。
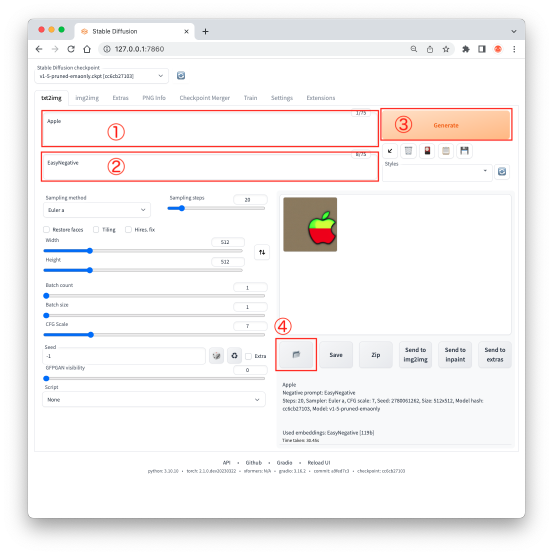
生成された画像ファイルの保存場所は、「④」のボタンをクリックすると、「txt2img-images」フォルダ内に「年-月-日」フォルダが作られ、その中に格納されます。

通常は、「stable-diffusion-webui\outputs\txt2img-images」フォルダに「年-月-日」フォルダが作られます。
よく利用する各パラメータの概要

Sampling method
さまざまなサンプラーがあり、変更することで絵のスタイルが変わります。モデルによって、推奨サンプラーが指定されている場合もあります。
Sampling steps
画像をか書き込むステップ数を指定します。通常は 20 〜 60 がよく利用されます。数字が大きくなるほど画像生成時間が長くなります。
Width
画像の横幅をピクセルで指定します。
Height
画像の縦幅をピクセルで指定します。
CFG Scale
数字が大きいほどプロンプトの要素に忠実な絵を作ろうとしますが、品質が落ちやすくなります。反対に数値が小さいと品質が向上し、プロンプトへの忠実度が低下します。通常は 7 〜 11 がよく使われます。
Seed
シード値を固定すると同じキャラクターの画像を生成しやすくなり、バージョン作りやすくなります。ランダムにキャラクターを生成するときには「-1」を指定します。
Script
各種スクリプトを使って画像生成を実行することができます。上級者向けの機能です。
モデル別の画像生成

Stable Diffusion で使用するモデルによって、画像がどのように変化するか比較してみます。Hugging Faceや CIVITAI などにさまざまなモデルが公開されています。他にもモデルを公開しているサイトが複数あります。作成したい画像のスタイルに応じて選ぶと良いでしょう。
モデルと VAE をダウンロード
anything-v4.0 は、アニメ風の画像を生成するのによく利用されます。Hugging Face のページを開いて、「Files」から「anything-v4.0.ckpt」のモデルと「anything-v4.0.vae.pt」の VAE フィアルがダウンロードできます。同じページに「anything-v4.5.ckpt」のモデルも同じページにあります。
アニメ風の画像生成によく利用される Counterfeit-V2.5 もよく利用されます。Hugging Face のページからモデルや VAE をダウンロードできます。「Files and versions」から「Counterfeit-V2.5.safetensors」のモデルと「Counterfeit-V2.5.vae.pt」の VAE フィアルがダウンロードできます。
モデルファイルはファイル名の最後が「.ckpt」と表示されています。Stable Diffusion モデルの格納場所は、「stable-diffusion-webui」→「models」→「Stable-diffusion」フォルダです。
VAE とは
Stable Diffusion の VAE(Variational Autoencoder)と呼ばれ、複数の種類があります。これを入れ替えると出力される画像が変化ます。通常はモデルと一緒に利用するので、同じ場所に公開されていることが多いです。
VAE ファイルはファイル名が「.vae.pt」で終わるものです。VAE ファイルの保存先は、「stable-diffusion-webui」→「models」→「VAE」フォルダです。
画像生成の比較実験
ここでは、anything-v4.0-pruned / anything-v4.5-pruned / Counterfeit-V2.5_pruned / v1-5-pruned-emaonly のモデルで画像を生成して比較してみます。画像はランダムに生成されるため、同じモデルでも全く同じものを作れません。ここでは、モデルによってどのような画像スタイルになるのか比べてみます。
AUTOMATIC1111 のページでは、以下のような設定で画像を生成してみます。比較のために、各モデルで4つの画像を作ることにします。ここでは、歩道を歩く学生服を来た女性を描いてみます。
| Prompt | ((masterpiece)), high quality, (blurry city street background:1.4), people, Close-up, professional Professional very Soft Portrait Lighting, physically-based rendering, beautiful, (1 woman from medieval Norse mythology, high nose, beautiful brown eyes, beautiful ponytail straight medium hair:1.2), (big breasts:1.3), ((18 years old)), (school white uniform, navy color skirt:1.3), [happy, smile], walking on sidewalk, looking away |
| Negative prompt | ((EasyNegative:1.2)), ((text:1.4)), ((logo:1.4)), (worst quality:1.4), (low quality:1.4), (monochrome:1.1), nsfw, shade, frame, no face, no head, fat, ((grayscale)), skin spots, thick eyebrows, acnes, skin blemishes, age spot |
| Steps | 20 |
| Sampler | DPM++ 2M Karras |
| CFG scale | 7 |
| Seed | 932821652 |
| Size | 512×512 |
| Model hash | c4ff51422a / e4b17ce185 / a074b8864e / cc6cb27103 |
| cc6cb27103 | anything-v4.0-pruned / anything-v4.5-pruned / Counterfeit-V2.5_pruned / v1-5-pruned-emaonly |
画像スタイルの比較
生成された画像は次のようになりました。それぞれ 25% に縮小しています。画像のスタイルの違いを見ていただければと思います。同じ条件で4枚の画像を生成していますが、これだけ画像が変わります。




Stable Diffusion の V1.5 (v1-5-pruned-emaonly)は、リアルな画像を生成するためのモデルですので、他とはかなりスタイルが異なります。着ている服は学生服なのか不明です。
モデルがどんな画像を学習したかによって作れる画像が異なります。作りたい画像のイメージに合ったモデルを選ぶのは大切なポイントになります。
処理速度の比較
また、各モデルで処理速度を比較してみます。macOSのターミナルアプリに処理速度が表示されます。「20/20」のあとの「[」から「<」の間にあるのが処理時間(分:秒)です。モデルが違ってもほぼ同じ秒数で画像が生成されています。




好みの画像を生成されるように、プロンプトやネガティブプロンプトを工夫します。
プロンプトとネガティブプロンプトとは

プロンプトとは、人工知能が与えられた情報や指示のことを指します。人工知能が与えられた情報をもとに、学習や判断を行います。
ネガティブプロンプトとは、人工知能が与えられた情報の中で、望ましくない情報や不適切な情報を示すものです。例えば、迷惑メールやスパムメールのように、ユーザーが受け取りたくない情報を示すことがあります。
一方、プロンプトは、人工知能が学習や判断を行うために必要な情報です。例えば、画像生成AIを使う場合、生成したい画像の種類や色、形状などの情報を与える必要があります。このように、プロンプトは人工知能が正確な判断を行うために必要な情報です。
しかし、ネガティブプロンプトが与えられた場合、人工知能は望ましくない情報を学習してしまう可能性があります。例えば、偏見のある言葉や人種差別的な表現を含む情報を与えた場合、人工知能がそれを学習してしまい、望ましくない結果を導くことがあります。
プロンプトの書き方

プロンプトは、人工知能が学習や判断を行うために必要な情報です。プロンプトを正確に書くことで、人工知能が望ましい結果を導くことができます。以下は、プロンプトの書き方のポイントです。
入力情報を具体的に指示する
プロンプトは、画像の生成に必要な入力情報を指示するものです。入力情報は、具体的で詳細な指示が必要です。例えば、画像を生成する場合は、画像の種類、色、サイズ、形状、背景色など、必要な情報を具体的に指示することが重要です。
誤解を招かないように注意する
プロンプトには、誤解を招かないように注意することが重要です。例えば、文字の色を生成する場合、色名だけでなく、RGB値なども指示するとより正確な結果を得ることができます。
プロンプトに書くテキストを要素ごとに分ける
AUTOMATIC1111 では 150文字まで、Stable Diffusion は75要素までが有効です。これを超えるプロンプトは無視されます。
プロンプトには、以下のような要素を文章で表現することができます。画像の要素を文章で表現するには、これらの要素を組み立てることが必要です。
- 画風、スタイル、カラートーン、クオリティー
- 背景、景色、昼 / 夜、天気
- 照明、ライティング
- カメラなどの撮影機材
- 人、人種、性別、年齢、容姿、体格、肌の色、肌の質、髪の色、髪の毛の質など
- ポーズ、行動、行為など
- 表情、目、瞳、眉毛、耳、口、唇、歯、鼻、顎、ヒゲなど
- 上半身、服装、色、装飾など
- 下半身、服装、色、装飾など
- 動物、物、小物、アクセサリー、メガネなど
上記以外の要素も考えられると思います。例えば、映画やドラマのワンシーンのような画像を作りたいとか、雑誌の表紙のような画像を作りたいとかあるでしょう。
AIコスプレイヤー、AIグラビアモデルのような画像を作りたいかもしれません。こうした好みを表現する要素をプロンプトに入力します。AIイラスト投稿サイトやTwitterなどでもプロンプトの例を見ることができますので、それらを参考にするとよいでしょう。
また、プロンプトへの入力は英語で行います。英単語を知っていると何かと便利です。以下の記事で紹介している単語学習方法も参考にしてみてはいかがでしょうか。

画像生成 AI は、英単語をキーワードとして使うので、中学校で習うレベルの英語がわかると困ることはないでしょう。
ネガティブプロンプトの書き方

ネガティブプロンプトは、人工知能が学習するために与える情報の一つで、望ましくない情報や不適切な情報を示します。ネガティブプロンプトは、要素が多すぎても機能しないことが多いです。
一般的な失敗画像は、「EasyNegative」で防ぐことができます。画像生成をしてみて、好ましくない部分だけを抑制するために、要素を追加するとよいでしょう。ネガティブプロンプトを書く際には、以下のポイントに注意する必要があります。
望ましくない情報を明確にする
ネガティブプロンプトを書く際には、何が望ましくない情報を明確にする必要があります。例えば、不適切な表現や差別的な言葉など、何を避けるべきかを明確に記述することが重要です。
具体的な例を挙げる
ネガティブプロンプトは、抽象的な表現になりがちです。具体的な例を挙げることで、ネガティブプロンプトをより具体的に指示することができます。例えば、性別や人種に関する不適切な表現を避けるように指示する場合、具体的な例を挙げることで、より明確な指示を行うことができます。
画像生成 AI が苦手とする画像

画像生成 AI は、多くの場合、高品質で美しい画像を生成することができます。しかし、以下のような場合には苦手とすることがあります。
複雑な構造を持つ画像
複雑な構造を持つ画像は、画像生成 AI にとって難しい課題となります。例えば、自然風景や建物のような複雑な構造を持つ画像は、細かい部分まで正確に再現することが難しく、歪んだ画像が生成されることがあります。
離散的な画像
画像生成 AI は、連続的なデータを扱うことが得意です。しかし、離散的なデータを扱うことが苦手です。例えば、文字や数字などは離散的なデータであり、画像生成AIが再現することが難しい場合があります。
特定のカテゴリに偏った画像
画像生成 AI は、学習に用いたデータに偏りがある場合、その偏りが再現されることがあります。例えば、犬の画像ばかりを学習させた場合、犬以外の画像を生成することが難しくなる場合があります。
画像としての明確な形がない画像
画像生成 AI は、明確な形を持つ画像を生成することが得意です。しかし、形が曖昧な画像やテクスチャなど、画像としての明確な形がないものは、再現することが難しい場合があります。
画像編集で精度向上
AIアートを作るのが好きになると、マンガやWebtoonを作りたくなります。
Stable Diffusionが生成する画像は、指とか、髪の毛など細部を修正したいときもあります。
そんなときには、フォトレタッチソフトよりもグラフィックソフトの方が向いています。
そんなときに、このソフトがおすすめです。

マンガやWebtoonの制作に最適な機能があり、ビジネス利用にも耐えられる高度な機能を備えています。
実は、仕事でもマンガやWebtoonを制作していますが、このソフトを使っています。
ユーザーが一番多いので、たくさんの情報がWebサイトや動画で見つかります。
パソコン版とタブレット版でファイルが連携できるのも良いです。
タブレットならペンでお絵かき楽ですし、パソコンならネームからマンガやWebtoonの完成までの編集作業に最適です。
グラフィックソフトを併用して、もっと高品質なAIアートを作れるようになります。
まとめ
この記事では、お手持ちのM1 Mac で Stable Diffusion を使えば、高価なコンピューターを持っていなくても、簡単に画像生成AIを始めることができます。手軽に画像生成AIを始めることができるようになります。
M1 Mac を使って手軽にできる画像生成 AI 「Stable Diffusion」と「AUTOMATIC1111」を利用して、初心者の方でも画像生成が行えるよう、基本的な使い方や始め方を丁寧に解説しました。
AIアートづくりはとも手も楽しいので、たくさんの方に楽しんでいただければ嬉しいです。AIアートを通じて、外国人との交流も良い体験になります。Discordなどでボイスチャットするときには、英語が話せると画像生成 AI の最新情報が得られます。また、Hugging Faceや CIVITAI などのサイトからモデルを探すときにも英語が読めると便利ですよ。オンライン英会話スクールの比較記事もあります。興味がありましたら、合わせてご覧ください。

これできっとあなたも、AIアートにハマること間違いなしです。完成したAIアートは、TwitterやInstagram、画像投稿サイト(Pixiv、Pinterest、ArtStation、AIピクターズなど)に公開して、交流を広めてみてはいかがでしょうか?